KEY TAKEAWAYS
-
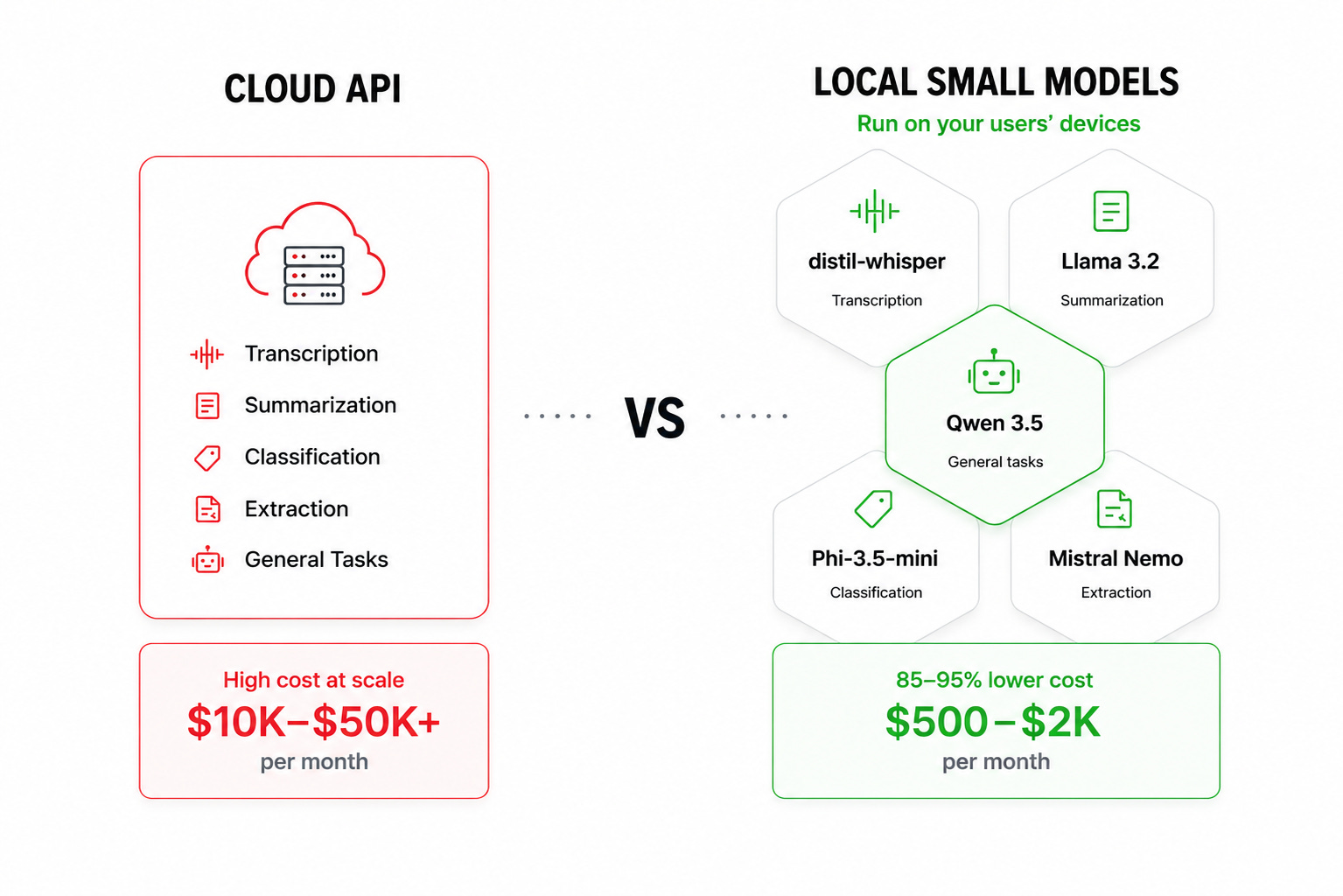
Most SaaS AI features are the same bounded task repeated thousands of times a day — transcription, summarization, transcript analysis, extraction, classification. These don’t require frontier models
-
Small language models (3-7B parameters) now power production chatbots, automation workflows, and high-throughput SaaS features where latency and cost matter more than raw model size
-
distil-whisper on an M1 8GB MacBook typically handles standard English meeting audio at 2-4s latency with a 2-2.5% word error rate — 85-95% cost reduction vs OpenAI Whisper API
-
Llama-3.2-3B on average produces meeting summaries in under a second on Apple Silicon. 90-100% of summarization workloads are typically replaceable locally
-
A Bank of England working paper (Buckmann & Hill, 2025) found quantized Llama 7B matched or beat GPT-4 on 17 classification tasks with 60-75 labeled samples — no fine-tuning
-
CPU-only Windows machines and non-English audio are real constraints. Local LLM deployment works best today for B2B products with controlled hardware environments
-
The models can handle these tasks. Shipping local LLM inference to users’ devices — handling hardware variance, cold starts, and fallback logic — is the engineering problem that remains
Most SaaS teams default to cloud APIs for AI features because they assume small models aren’t good enough
For most of what those features actually do, that assumption is wrong. Local LLMs can handle most SaaS product features in production today. The distinction that matters is task type. Complex reasoning, multi-step agentic workflows, frontier-level synthesis — cloud APIs still win there. But transcription, summarization, transcript analysis, document extraction, and classification? Small language models running locally typically handle these well on consumer hardware right now, and the benchmark numbers back that up.
What AI tasks do most SaaS products actually run?
Most SaaS AI features share a common profile: fixed input, fixed output schema, same task repeated at scale. A meeting intelligence tool typically runs the same transcription pipeline hundreds of times a day. A support tool runs the same ticket classification logic on every incoming request. A document tool runs the same extraction prompt on every uploaded file.
The three highest-ROI LLM use cases for SaaS in 2026 are real-time content moderation, customer support ticket summarization, and personalized recommendations using semantic embeddings. None of these require a 70B parameter model or multi-step reasoning across a 200k context window. They require a model that’s fast, consistent, and accurate enough — running on a fixed task it can be optimized for.
This is the category where local LLM deployment changes the economics. Small language models now power production chatbots, agent pipelines, and high-throughput automation workflows where latency, cost, and operational simplicity matter more than sheer model size.
How do small local models perform on SaaS production tasks?
Here’s what real numbers look like running local LLM inference on Apple Silicon hardware across four common SaaS task types.
Transcription: distil-whisper on an M1 8GB MacBook typically handles standard English meeting audio at 2-4s latency with a 2-2.5% word error rate, 650MB peak RAM, and an RTF of 0.15-0.25x. A 60-minute meeting can be processed in under 10 minutes. In testing, 85-95% of standard English meeting transcription workloads are typically replaceable locally, with cost reduction of the same magnitude versus the OpenAI Whisper API at $0.006/minute.
Summarization: Qwen3.5-4B and Llama-3.2-3B on 8-16GB Apple Silicon on average produce meeting summaries with time-to-first-output of 0.2-0.7s, 2.7-4.5GB peak RAM, stable performance across meeting lengths. 90-100% of summarization workloads typically run fine on current consumer hardware.
Transcript analysis: Llama-3.2-3B (2.2GB, Q4_K_M) running on an 8GB M1 typically handles meeting transcript analysis, extracting decisions, action items, and the reasoning behind them, with 80-90% of standard transcript analysis workloads typically replaceable locally.
Classification: A Bank of England working paper (Buckmann & Hill, 2025, arxiv.org/abs/2408.03414) tested quantized Llama 7B against GPT-4 across 17 sentence classification tasks. With 60-75 labeled samples, the small local model matched or beat GPT-4. No fine-tuning required.
Why do optimized small models sometimes outperform frontier models on specific tasks?
Frontier models are generalists. They’re trained across thousands of task types to maximize performance on benchmarks that span everything from creative writing to advanced mathematics. That generality comes at a cost: compute spread across capabilities you don’t need for a single, bounded task.
A domain-optimized 3B model for meeting summarization focuses all its capacity on one job. A well fine-tuned small language model can outperform a much larger general-purpose LLM on domain-specific tasks. Lower compute waste, lower latency, more consistent output schema, and a memory footprint that fits on hardware your users already own.
This isn’t a new insight in machine learning — specialized models have always outperformed generalists on narrow tasks. What’s changed is that the baseline capability of small models has improved enough that you’re not trading accuracy for efficiency. For classification, summarization, and transcript analysis, a well-configured local 3-7B model isn’t a compromise. For many SaaS workloads it’s often the better tool for the job.
When does local LLM deployment NOT work for SaaS products?
This doesn’t work for every product today. Knowing the constraints is what separates a realistic local LLM deployment from one that breaks in production.
CPU-only Windows machines are the biggest hardware constraint. Inference typically runs 5-10x slower without GPU acceleration, and real-time features become unviable. If your SaaS serves a broad general consumer base on unknown hardware, you’ll likely hit this frequently.
Task constraints are equally real. Heavy accents, noisy audio, and non-English input still tend to push to cloud for transcription accuracy. Complex multi-step reasoning, long context synthesis, and tasks requiring world knowledge beyond training data remain firmly in frontier model territory.
The hardware environment your users are in determines your viable path. Enterprise teams on MacBooks, developer tools, B2B products with a controlled device environment — these can typically go mostly local today. Broad consumer SaaS with unknown hardware needs honest cloud fallback logic for a meaningful portion of requests.
How does running LLMs locally compare to cloud APIs for SaaS cost?
The cost difference at scale is significant. OpenAI Whisper API runs at $0.006/minute of audio. For a 100-person team running 5 hours of meetings per week, that’s roughly 30,000 minutes per month — around $180/month for transcription alone, before summarization or any other AI features.
For summarization, GPT-4o-mini runs at $0.15-$0.60 per million tokens. A typical 60-minute call summary uses around 4,000 input tokens plus 600 output tokens. At 10 meetings/day across 1,000 users, that’s around $300/month for summarization alone.
A fintech company reduced its monthly AI costs from $47,000 to $8,000 — an 83% drop — by shifting high-volume tasks to local models and using cloud APIs only for complex tasks. On-device inference for high-frequency, bounded SaaS tasks can eliminate per-token billing entirely for those workloads. The hardware typically already exists on your users’ machines.
The cost argument is strongest for products where the same AI feature runs frequently per user session. Transcription, summarization, and transcript analysis running dozens of times per user per day — those are the workloads where local LLM deployment can change the unit economics.
What’s the real challenge of shipping local LLM inference in a SaaS product?
The models can handle these tasks. The harder problem is getting them onto hardware you don’t control.
Running LLMs locally on your development machine is straightforward. Shipping that same local inference as a feature in a product your users depend on means solving three problems: hardware variance across your user fleet, cold starts that break the UX when models aren’t preloaded, and fallback logic when a device can’t cope with the inference load.
The honest limitations deserve equal weight — a locally run 8B parameter model won’t match GPT-4o on complex reasoning tasks. The practical answer for most SaaS products is hybrid routing: local for the high-frequency bounded tasks covered in this post, cloud for anything requiring frontier capability.
Locai is built specifically for the infrastructure problem — device registration, fleet management, model deployment across user hardware, and automatic cloud fallback when a device can’t handle the load. An OpenAI-compatible API means existing code needs one line changed to point at local inference. Learn how on-device AI inference works in production.
Frequently asked questions about local LLMs for SaaS
Can a 3B or 7B model replace GPT-4 for SaaS product features? For bounded, repeated tasks with fixed input and output schemas — transcription, summarization, transcript analysis, classification, extraction — yes, in many cases. A Bank of England working paper found quantized Llama 7B matched or beat GPT-4 on 17 classification tasks with 60-75 labeled samples. For complex multi-step reasoning, long context synthesis, or tasks requiring broad world knowledge, frontier models still tend to outperform small local models.
What SaaS tasks can local LLMs handle in production? Transcription, meeting summarization, transcript analysis and action item extraction, document extraction and classification, support ticket routing, and content moderation are all typically viable for local LLM deployment today. These tasks share a profile: fixed input schema, fixed output format, no multi-step reasoning required. They represent the majority of AI features in most SaaS products.
How accurate are small local models for transcription? distil-whisper on an M1 8GB MacBook typically achieves a 2-2.5% word error rate on standard English meeting audio — comparable to cloud transcription services in most conditions. Performance tends to degrade on heavy accents, background noise, and non-English audio, where cloud APIs still generally outperform local models.
What hardware do users need to run local LLM inference? Apple Silicon Macs (M1 and later) with 8-16GB unified memory typically handle 3-8B models well. NVIDIA GPUs with 8GB+ VRAM on Windows and Linux are also viable. CPU-only machines are the real constraint: inference is typically 5-10x slower without GPU acceleration, making real-time features unviable on CPU-only hardware.
How much does it cost to run AI inference locally versus cloud APIs? Local inference can eliminate per-token and per-minute API costs entirely for workloads handled on-device. OpenAI Whisper API costs $0.006/minute; a 100-person team running 5 hours of meetings per week typically spends around $180/month on transcription alone. GPT-4o-mini summarization adds roughly $300/month at 10 meetings/day for 1,000 users. Shifting high-frequency bounded tasks to local inference removes these costs at the hardware level.
When should a SaaS product use a local model versus a cloud API? Local models tend to fit best for high-frequency, bounded tasks on known hardware with privacy requirements or meaningful inference cost. Cloud APIs remain the right choice for complex reasoning tasks, infrequent inference where latency isn’t critical, or products with a broad general consumer base on unknown hardware where CPU-only machines are common.
What is a small language model (SLM)? A small language model is a language model with 1-7 billion parameters, designed to run efficiently on consumer hardware. SLMs trade some of the general capability of larger frontier models for lower latency, lower compute requirements, and easier deployment. Well-optimized SLMs can often outperform larger general-purpose models on specific production tasks they’ve been tuned for.
How do you deploy local LLM inference to end-user devices in a SaaS product? The main challenges are hardware variance across user devices, cold starts when models aren’t preloaded, and fallback routing when a device can’t handle the load. Tools like Locai provide the orchestration layer — device registration, model deployment, fleet management, and automatic cloud fallback — with an OpenAI-compatible API requiring minimal code changes.