Cut your inference bill 60%+. Keep user data on their device.
Route inference to your customers' idle compute — without changing a line of your product code. The same sovereign-AI platform regulated enterprises run, packaged as an SDK.
Every prompt your users send is a tax on your gross margin.
AI-feature COGS now eat what used to be SaaS profit. Your CFO has noticed.
Inference costs scale linearly with usage. Your pricing doesn't.
Every token routes through someone else's infrastructure. You own none of it.
You're shipping the AI feature. Someone else is keeping the margin.
The AI gross-margin gap.
25–30 points of gross margin are walking out the door on every prompt. CFOs are publicly modelling this in board materials.
Sources — ICONIQ 2026 State of AI (~300 AI product execs); SaaS CFO benchmark via Ben Murray, Apr 2026.
Your customers are paying twice.
Once for the MacBook, iPhone, or workstation they already own — loaded with 4+ generations of Apple Silicon or NPU-class compute.
Then again, every time you bill them — for a cloud GPU that's slower, more expensive, and less private than the silicon already on their lap.
500ms RTT · usage-priced · margin destroyed.
On-device · zero RTT · zero marginal cost.
Your existing OpenAI client — pointed at your customer's laptop.
Loc.ai:Link
Embeds inside your product. Turns each user device into an OpenAI-compatible inference node.
Loc.ai:Control
Push and manage models on your fleet of nodes. Pick what runs where, version, and roll back.
Redirect the API
Your existing call site stays the same — just point baseURL at the user's device endpoint. Done.
const openai = new OpenAI({
baseURL: "https://api.openai.com/v1",
apiKey: process.env.OPENAI_KEY,
});
const openai = new OpenAI({
baseURL: locai.endpoint(user.id),
apiKey: process.env.LOCAI_KEY,
});
// That's the integration.
// The rest is config.
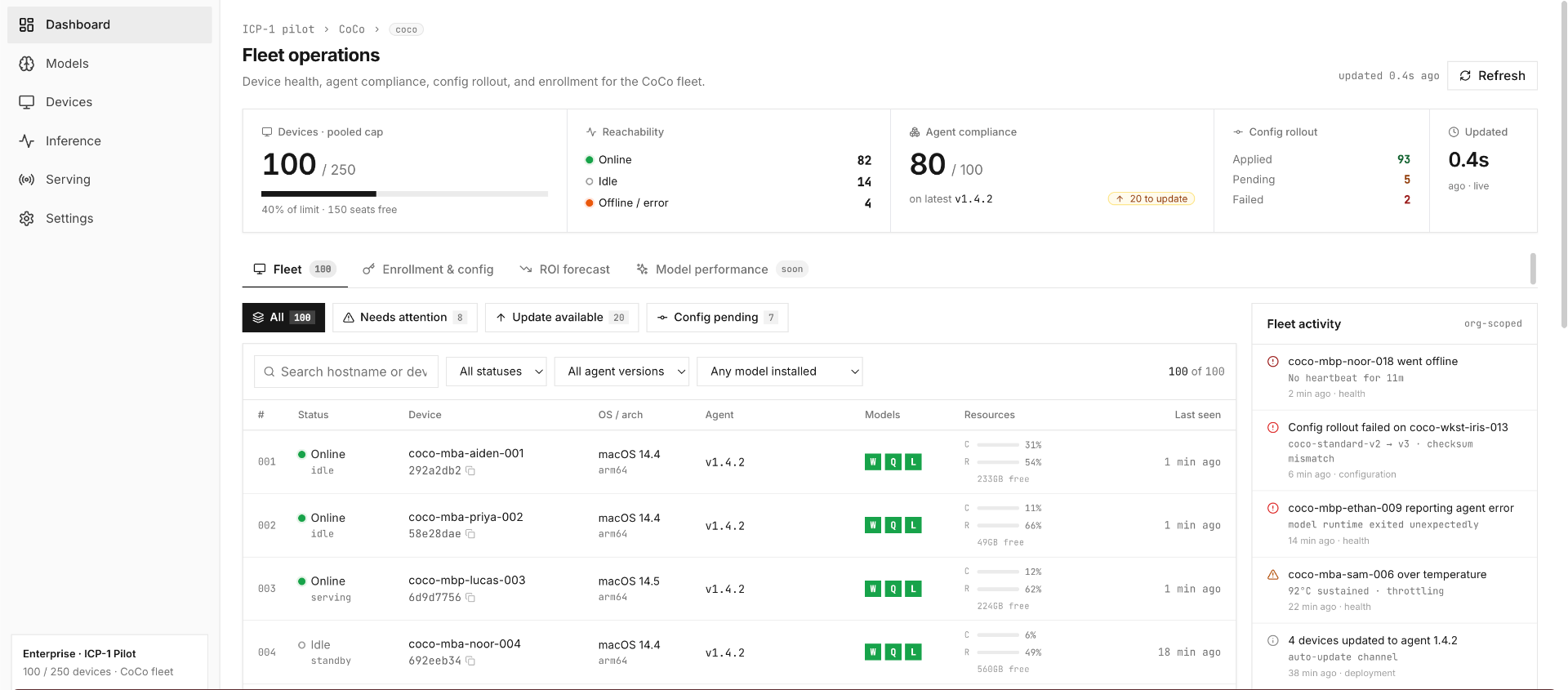
Manage every node in your customer fleet from one place.
Device health, agent compliance, config rollout, and model management across your entire user base — without touching a single customer device.
You're a perfect fit if your product looks like this.
AI is core to your product
Not a side feature — the thing users come back for.
Most users are on capable devices
MacBooks, modern PCs, recent iPhones, iPads. Apple Silicon-class or better.
Your workloads fit a 1–13B model
If trained properly. Most chat, summarisation, agents, and structured tasks do.
Inference cost is a top-3 line item
Or it will be by next quarter at your growth rate.
Latency matters
Users notice the half-second round-trip. Local is instant.
The focused AI workflow.
A focused AI workflow — meeting notes, agentic copilots, research assistants, vertical SaaS — where the user is sitting at a Mac, the task fits a small model, and a 500ms cloud round-trip is the worst part of the experience. If your roadmap says "figure out how to bring AI costs down before Series B" — this page is for you.
From 50% back to 75% on every $100 of revenue.
30-point compression from a single product decision.
83% reduction in AI COGS · 25 points recovered.
Recovered margin doesn't just sit there — it cascades through every metric your board cares about.
Worked example after Ben Murray, The SaaS CFO, Apr 2026. Loc.ai-side numbers are illustrative; real savings modelled per workload during pilot.
Two things AI teams get wrong — and one thing the biggest CFO in software just confirmed.
"Small models can't replace big models."
They can — when trained correctly.
A properly fine-tuned 7–13B model matches GPT-class quality on the narrow tasks SaaS products actually run: extraction, summarisation, structured generation, in-domain agents. The frontier-model arms race is for general intelligence — you're shipping a specific feature.
"Customers can't run AI locally."
They've been running it for 4 years.
Apple Silicon shipped in 2020. Every M-series Mac, every iPhone since the 15 Pro, and most modern Windows machines have NPU-class compute that idles 99% of the time. Your users own better inference hardware than your cloud provider rents to you per token.
Salesforce just processed ~20T tokens. And the CFO is publicly committing to drive that cost down.
"Tokens... are going to start to go down over time and commoditize... engineering and product is working on ways to reduce the overall cost."
— Robin Washington, Salesforce COFO, Q4 FY26 earnings call.
Translation: every public AI buyer is now under board pressure to cut inference. We are how you cut it.
The only option that scales out to your users.
| Capability | OpenAI / Anthropic | Bedrock / Together / Fireworks | DIY on-device | Loc.ai |
|---|---|---|---|---|
| 60%+ COGS reduction | ✗ | ~ | ✓ | ✓ |
| Drop-in OpenAI compatibility | ✓ | ✓ | ✗ | ✓ |
| Sub-100ms latency | ✗ | ✗ | ✓ | ✓ |
| User data stays on device | ✗ | ✗ | ✓ | ✓ |
| No infra to operate | ✓ | ✓ | ✗ | ✓ |
| Fleet-scale model management | — | ~ | ✗ | ✓ |
| Time to integrate | Hours | Days | Months | Hours |
They sell you tokens. We sell you margin back.
They host GPUs. We make GPUs irrelevant for most workloads.
You'd spend 6 months. We're 1 SDK and a config change.
A credible path back to 75%+ gross margin.
Drop the SDK in
Free starter tier. Point your OpenAI client at a Loc.ai endpoint. First on-device prompt running on your own laptop, same afternoon.
Pick the wedge workload
Together we identify the feature where small-model quality + on-device latency wins hardest. Usually obvious in a 30-min call.
Live on a sub-cohort
Roll out to a slice of your users with cloud fallback. Measure real cost & latency deltas. Real numbers replace illustrative ones.
Scale across product
Expand to remaining workloads. Track AI COGS as a % of AI revenue. We get paid on what we save you.
SOC 2 in progress. Models and data never leave the user's device. Zero-knowledge fallback when cloud is needed.
Calculate Your Savings
See how much you could save by shifting inference to the edge
Save 79% with Loc.ai
✅ Fixed-cost infrastructure scales better than Cloud APIs.
Based on 3:1 input/output ratio. Cloud prices from public API rates.
Try it tonight. Or talk to us tomorrow.
Hop on the starter tier — free.
Drop the SDK in, point your OpenAI client at a Loc.ai endpoint, and see your first prompt run on-device. Takes an afternoon. No card.
Start free30-min technical deep-dive.
Walk us through your workload. We'll model your specific savings, show the architecture, and scope a 4-week paid pilot.
Book a call