
KEY TAKEAWAYS
-
At scaling-stage AI SaaS companies, inference now averages 23% of total revenue (ICONIQ Capital, January 2026), compressing average gross margins to 52% against the 70-85% traditional SaaS benchmark
-
Most teams respond with the same toolkit: cheaper models, semantic caching, prompt compression, token limits, tiered routing. All valid. All optimizations on top of the same architecture where every request still hits a paid cloud API
-
On-device inference is widely underestimated as a solution: the assumption that local models aren’t production-ready is increasingly wrong for bounded SaaS tasks, and the production infrastructure to ship it reliably has only become viable recently
-
Moving 60-80% of requests to user hardware on conservative thresholds eliminates per-request API costs for those workloads. The variable cost shifts from your P&L to hardware your users already own
-
The actual blocker isn’t model capability. It’s production infrastructure: fleet management, hardware variance across user devices, cold starts, and reliable cloud fallback
-
Locai is a device-first AI infrastructure company that handles this orchestration layer (device registration, fleet management, model deployment, and cloud fallback) with a single baseURL change to your existing OpenAI client.
On-device inference is one of the least explored options for reducing AI inference costs in SaaS products — and one of the most structurally effective for the right workloads. Most founders have already tried the obvious moves: routing to cheaper models, adding semantic caching, compressing prompts, setting hard token limits, tiering model selection by task complexity. The bills are still climbing. That’s not a toolkit problem. It’s an architecture problem: every optimization still assumes every request goes to a cloud API. On-device inference runs inference on your users’ devices by default and routes to cloud only when needed, eliminating per-request costs for the workloads it handles.
Why are AI inference costs compressing SaaS gross margins?
At scaling-stage AI SaaS companies, inference now averages 23% of total revenue, according to ICONIQ Capital’s January 2026 State of AI report (via SaaStr). Average gross margins for AI-native products are projected at 52% in 2026, up from 41% in 2024 as operators learn to manage costs, but still 20-30 points below the 70-85% that traditional SaaS typically targets.
The gap is structural. Inference cost sits in COGS as a variable expense that scales with every user, session, and AI-powered interaction in your product. Adding an AI assistant to an $80-per-month seat can add roughly $15 in direct variable inference cost, dropping gross margin from 80% to closer to 65% on that seat immediately (Ben Murray, The SaaS CFO, April 2026).
Why doesn’t the standard cost-reduction toolkit solve this?
Most teams responding to AI inference cost pressure reach for the same set of tools. They are all legitimate responses to a real problem:
-
Route lower-complexity requests to cheaper, smaller models
-
Add semantic caching to avoid re-running inference on repeated or similar inputs
-
Compress prompts and trim conversation history to reduce token counts per request
-
Set hard token limits per session to cap worst-case costs
-
Tier model selection by task complexity: frontier models only for tasks that require them
-
Batch repeated requests where real-time response isn’t required
All of these work. None of them change the fundamental architecture. Every request still travels to a cloud API. Every inference call still generates a per-token cost. The floor on variable cost is determined by the cheapest model that produces acceptable output, not by zero. For products where AI features run frequently per user per session, this is a diminishing returns game: costs per token fall, but total spend rises as usage grows.
What does on-device inference change for SaaS unit economics?
On-device inference changes where computation happens. Instead of sending every request to a cloud API, inference runs on the user’s own device by default and routes to cloud only when the device can’t handle the load. The threshold is configurable.
The unit economics shift in a specific way. You stop paying per API call for the requests handled locally. The compute still happens — it just happens on hardware your users already own. At conservative thresholds, 60-80% of requests are handled locally in production. The variable cost for those requests moves from your P&L to your users’ hardware amortization.
Local inference for content moderation delivers sub-500ms latency, with local inference cost approximately $0.003 per 1K tokens, roughly 10x cheaper than GPT-4-based cloud moderation at $0.01-0.03 per 1K tokens (Markaicode, May 2026). For a product running moderation at scale, that difference is material. The latency improvement from 2 seconds to 450ms is equally significant for user experience. SSRN
How does on-device inference compare to cloud APIs and self-hosted models?
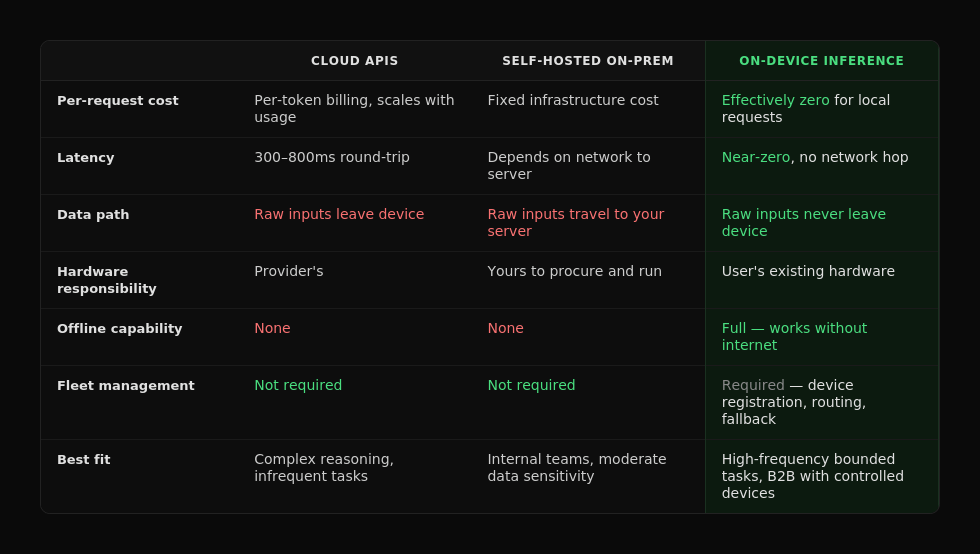
Which SaaS workloads are ready for on-device inference today?
Not all inference workloads move equally well to local models. The tasks that work best share a specific profile: fixed input schema, fixed output format, same task run repeatedly at scale, no complex multi-step reasoning required.
For a SaaS product, this covers more ground than most founders expect:
Transcription: distil-whisper on an M1 8GB MacBook typically handles standard English meeting audio at 2-4s latency with a 2-2.5% word error rate, using 650MB peak RAM. A 60-minute meeting processes in under 10 minutes. (Locai internal benchmarks, 2025-2026)
Summarization: Qwen3.5-4B and Llama-3.2-3B on 8-16GB Apple Silicon produce meeting summaries with time-to-first-output of 0.2-0.7s, 2.7-4.5GB peak RAM. 90-100% of summarization workloads are typically replaceable locally. (Locai internal benchmarks, 2025-2026)
Transcript analysis: Llama-3.2-3B (2.2GB, Q4_K_M) on an 8GB M1 typically handles meeting transcript analysis — extracting decisions, action items, and supporting reasoning — with 80-90% of standard workloads replaceable locally. (Locai internal benchmarks, 2025-2026)
Classification: A Bank of England working paper (Buckmann & Hill, 2025, arxiv.org/abs/2408.03414) tested quantized Llama 7B against GPT-4 across 17 sentence classification tasks. With 60-75 labeled samples, the small local model matched or beat GPT-4. No fine-tuning required.
The efficiency curve is also still moving. TurboQuant KV cache compression is being actively integrated into llama.cpp: 4.6x compression at under 1% accuracy loss, with a 22.8% decode speedup on Apple Silicon at 32K context length (megaoneai.com, March 2026).
Is on-device inference right for your SaaS product? A quick checklist
On-device inference is a strong fit if most of these apply to your product:
Your AI workload
-
Your AI features run the same task repeatedly — transcription, summarization, classification, extraction, or similar
-
Inputs and outputs follow a fixed schema, not open-ended generation or complex reasoning
-
AI features run frequently per user per session, not occasionally
Your users’ hardware
-
A meaningful share of your users are on Apple Silicon Macs (M1 or later), or Windows/Linux machines with NVIDIA GPUs (8GB+ VRAM)
Your cost situation
-
Inference cost is already a line item on your P&L that’s growing with usage
-
You’ve already tried model routing, caching, and prompt compression and the bill is still climbing
Red flags that suggest on-device isn’t the right fit yet
-
Your product serves a broad general consumer base on unknown or uncontrolled hardware
-
Your AI features require heavy accents, non-English audio, or frontier-level reasoning
If you checked most of the green items and none of the red flags, on-device inference is worth a serious evaluation for your product.
When does on-device inference not work for SaaS products?
CPU-only Windows machines run 5-10x slower without GPU acceleration and real-time features aren’t viable there. Heavy accents, noisy audio, and non-English input still push transcription to cloud for accuracy-critical applications. Complex multi-step reasoning, long context synthesis, and tasks requiring world knowledge remain in frontier model territory.
Products serving a broad consumer base on unknown hardware need honest cloud fallback logic for a significant share of requests.
Why aren’t more SaaS teams doing this already?
The model capability question is largely answered for bounded tasks. The infrastructure question is not.
Getting a model running locally on a developer’s machine is straightforward. Shipping that inference as a production feature means solving problems that don’t appear in benchmarks: hardware variance across your user fleet, cold start latency when models aren’t preloaded between sessions, fleet management when your users arrive with seven different chip configurations, and cloud fallback routing that degrades gracefully when a device can’t cope.
Two years ago the tooling to manage this in production didn’t exist in a form suitable for SaaS products. Building it from scratch adds months of engineering time before you ship a single user-facing feature. That’s the actual blocker, not model capability.
How does Locai approach on-device AI inference infrastructure?
Locai is a device-first AI infrastructure company that handles the orchestration layer between your application code and the inference runtime.
Locai runs inference locally on user devices by default and routes to cloud or on-prem only when a device can’t handle the load. The integration into an existing OpenAI-compatible application is a single line:
javascript
const openai = new OpenAI({
baseURL: "http://localhost:8100"
})Locai:Link is a lightweight runtime agent that runs continuously on the device, keeping models warm between requests so cold starts stop being a problem. Locai:Control handles device registration, model deployment, and workload routing across your fleet. Models run as GGUF via llama.cpp with no per-device setup required. The communication layer runs on Zenoh, a pub/sub protocol built for distributed low-latency edge workloads.
In production, most products see 60-80% of requests handled locally on conservative thresholds. Free tier: 3 devices, no card required, around 5 minutes to first inference.
Docs and quickstart at docs.locai.co.uk/docs
Frequently asked questions about on-device inference for SaaS
Why are AI inference costs so much higher than traditional SaaS COGS? Traditional SaaS COGS are mostly fixed infrastructure costs that don’t scale with individual user behavior. AI inference costs scale directly with usage: every request generates a per-token cost that compounds across every user, session, and AI-powered interaction. ICONIQ Capital’s January 2026 State of AI report puts inference at 23% of total revenue at scaling-stage AI B2B companies, a cost structure traditional SaaS financial models weren’t built for.
What is the average gross margin for AI SaaS companies in 2026? ICONIQ Capital’s January 2026 State of AI report projects average gross margins for AI-native products at approximately 52% in 2026, up from 41% in 2024 and 45% in 2025. Traditional SaaS companies typically target 70-85% gross margins. The gap is structural and driven primarily by inference cost sitting in COGS as a variable expense that scales with product usage.
What is on-device inference for SaaS products? On-device inference means running AI model inference directly on end-user devices rather than sending requests to a cloud API. In a SaaS context, the model runs on your user’s hardware by default and routes to cloud only when the device can’t handle the load. Per-request API costs for locally handled inference drop to effectively zero, shifting the compute burden to hardware users already own.
Which SaaS AI tasks work best with on-device inference? Tasks with fixed input schemas, fixed output formats, and no complex reasoning requirements move most reliably to local models. Transcription, meeting summarization, document extraction and classification, and transcript analysis are well within current local model capability on 8-16GB Apple Silicon. Tasks requiring frontier model reasoning, long context synthesis, or non-English audio still push to cloud.
How much does on-device inference cost compared to cloud APIs? For requests handled locally, the per-token cost is effectively zero: no API fees, no per-minute charges, no usage-based billing. The real cost is hardware amortization on devices users already own. Cloud API costs for comparison: OpenAI Whisper API runs at $0.006 per minute of audio, GPT-4o-mini summarization at $0.15-0.60 per million tokens. For a 100-person team running 5 hours of meetings per week, cloud transcription alone costs around $180 per month. Shifting 60-80% of that workload to on-device inference eliminates the variable cost for those requests entirely.
What hardware do end users need to run on-device inference? Apple Silicon Macs (M1 and later) with 8-16GB unified memory handle 3-8B models well for most SaaS inference tasks. NVIDIA GPUs with 8GB+ VRAM on Windows and Linux are also viable. These are the device profiles that typically appear in B2B SaaS with a controlled hardware environment: enterprise teams on company-issued MacBooks, developer tools, and regulated industries like legal and healthcare where devices are managed and modern. CPU-only machines run 5-10x slower without GPU acceleration, making real-time features unviable.
What infrastructure is required to ship on-device inference in a SaaS product? The serving layer — llama.cpp, Ollama — handles model execution and is largely solved. The harder infrastructure layer covers device registration and health monitoring, persistent model warm state to eliminate cold starts, intelligent routing between local and cloud, and centralized model deployment across a user fleet. Purpose-built tools like Locai handle this orchestration layer with an OpenAI-compatible API requiring minimal code changes.